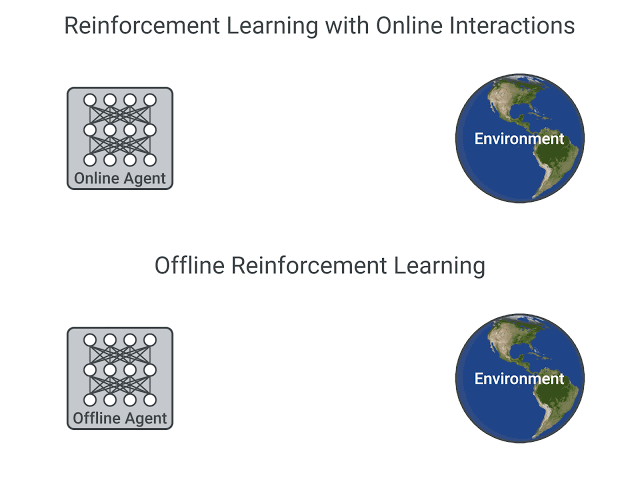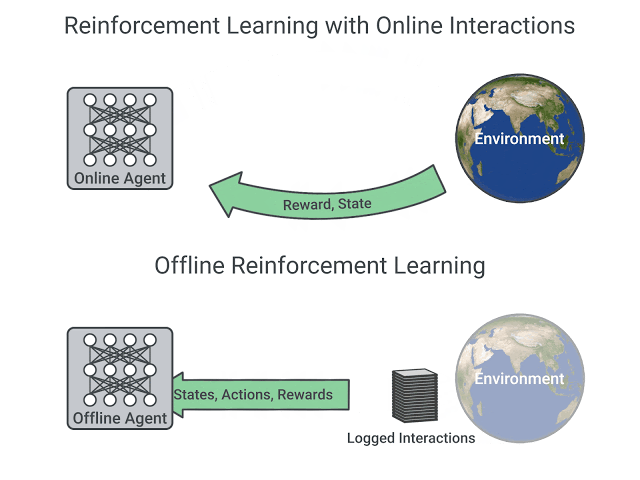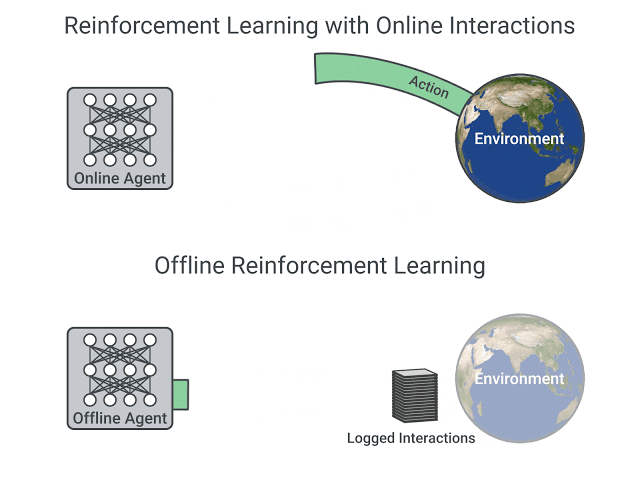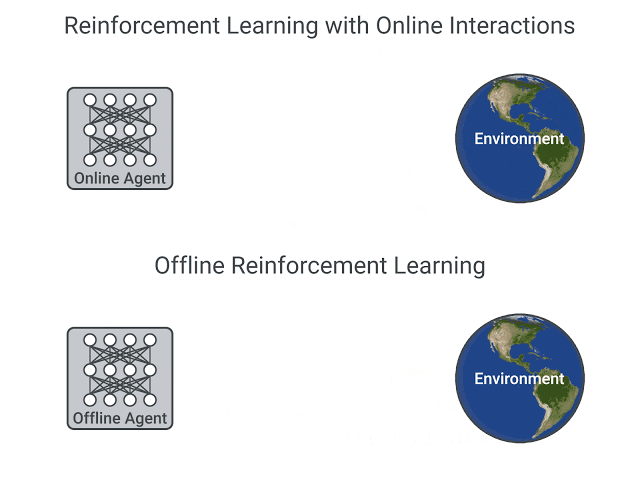
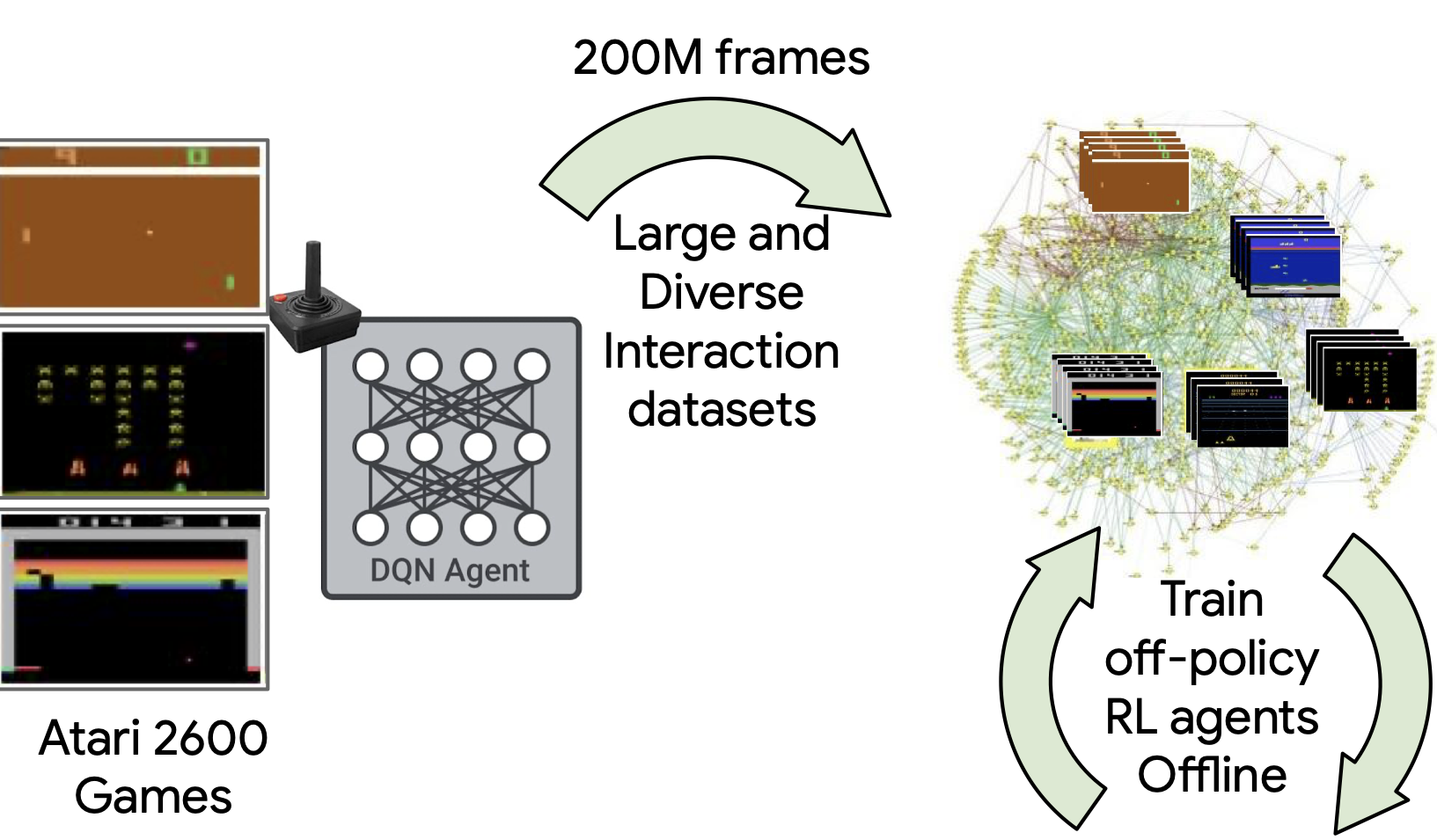
DQN Replay Dataset
The DQN Replay Dataset was collected as follows: We first train a DQN agent, on all 60 Atari 2600 games with sticky actions enabled for 200 million frames (standard protocol) and save all of the experience tuples of (observation, action, reward, next observation) (approximately 50 million) encountered during training. We repeat this process five times for each game.
Important notes on Atari ROM versions
The DQN replay dataset is generated using a legacy set of Atari ROMs specified in atari-py<=0.2.5, which is different from the ones specified in atari-py>=0.2.6 or in recent versions of ale-py. To avoid train/evaluation mismatches, it is important to use atari-py<=0.2.5 and also gym<=0.19.0, as higher versions of gym no longer support atari-py.
Alternatively, if you prefer to use recent versions of ale-py and gym, you can manually download the legacy ROMs from atari-py==0.2.5 and specify the ROM paths in ale-py. For example, assuming atari_py_rom_breakout is the path to the downloaded ROM file breakout.bin, you can do the following before creating the gym environment:
import ale_py.roms
ale_py.roms.Breakout = atari_py_rom_breakout
Note that this is an ad-hoc trick to circumvent the md5 checks in ale-py<=0.7.5 and it may not work in future versions of ale-py. Do not use this solution unless you know what you are doing.
Dataset and Training details
This logged DQN data can be found in the public GCP bucket
gs://atari-replay-datasets which can be downloaded using gsutil.
To install gsutil, follow the instructions here.
After installing gsutil, run the command to copy the entire dataset:
gsutil -m cp -R gs://atari-replay-datasets/dqn
To run the dataset only for a specific Atari 2600 game (e.g., replace GAME_NAME
by Pong to download the logged DQN replay datasets for the game of Pong),
run the command:
gsutil -m cp -R gs://atari-replay-datasets/dqn/[GAME_NAME]
This data can be generated by running the online agents using
batch_rl/baselines/train.py for 200 million frames
(standard protocol). Note that the dataset consists of approximately 50 million
experience tuples due to frame skipping (i.e., repeating a selected action for
k consecutive frames) of 4. The stickiness parameter is set to 0.25, i.e.,
there is 25% chance at every time step that the environment will execute the
agent’s previous action again, instead of the agent’s new action.
Citing
If you find this open source release useful, please reference in your paper:
Agarwal, R., Schuurmans, D. & Norouzi, M.. (2020). An Optimistic Perspective on Offline Reinforcement Learning International Conference on Machine Learning (ICML).
@inproceedings{agarwal2020optimistic,
title={An optimistic perspective on offline reinforcement learning},
author={Agarwal, Rishabh and Schuurmans, Dale and Norouzi, Mohammad},
booktitle={International Conference on Machine Learning},
year={2020}
}
Authors



For questions, please contact us at: rishabhagarwal@google.com, mnorouzi@google.com.